
IMPROVED YOLOV3 ALGORITHM for Pantograph safety state detection
2022-08-02 09:13Abstract: The pantograph is a critical component that connects the rolling stock to the power supply grid, so the safety status of the pantograph is vital to the smooth and stable operation of the rolling stock.
In this paper, by analyzing frame by frame, the pantograph video images monitored by the on-board video monitoring system, the safety status of the pantograph is monitored in real-time by modifying the YOLOV3 target recognition algorithm widely used in industry to identify structural abnormalities, sparks, and foreign object intrusion of the pantograph at the same time. Experiments have proven that a single channel can reach 40fps on a Tienuo on-board intelligent analysis server. The comprehensive detection accuracy mAP@0.5 can get 98%, achieving real-time and relatively accurate detection results.
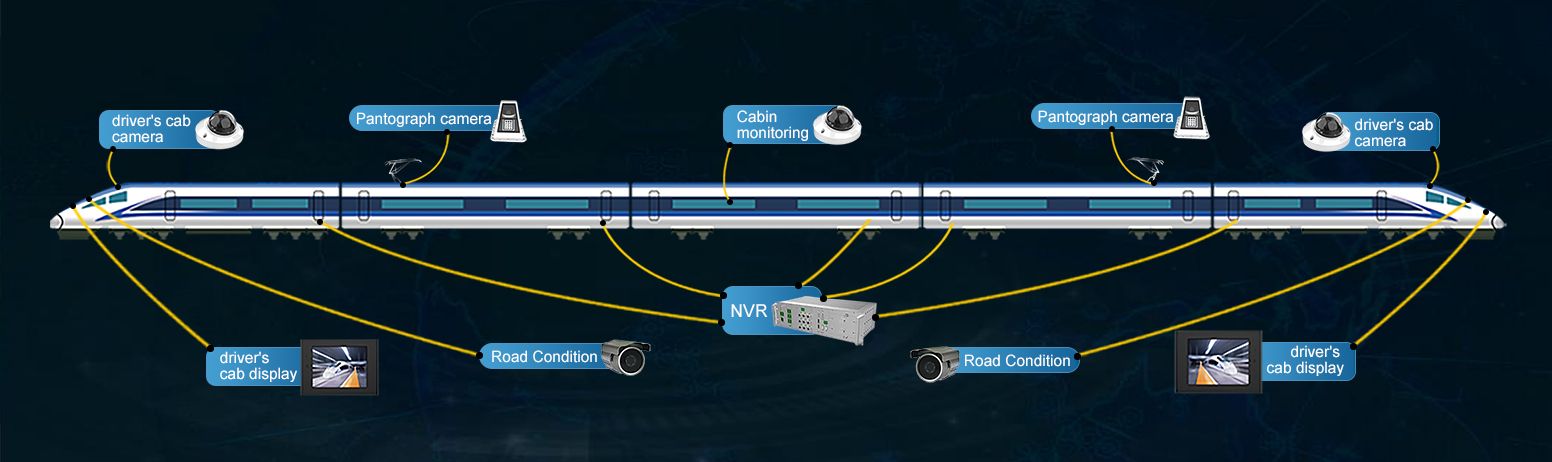
1. Intelligent surveillance of pantographs
Today's typical target recognition algorithms based on deep learning are two-stage algorithms such as the Faster R-CNN algorithm and single-stage algorithms such as the YOLOV3 algorithm.YOLO algorithm does not need to calculate the candidate frame in advance compared to the R-CNN network, which reduces the computational effort and can achieve faster computational speed. And the YOLOV3 algorithm improves the deficiency of multi-scale detection of the previous generation of the YOLO algorithm by having three branches in the recognition network part, which can cope with the problem of target recognition at three scales: small, medium, and large. In addition, the YOLOV3 algorithm has better engineering support and is used in industrial honor in a large number of applications. Therefore, in this paper, YOLOV3 is chosen as the basis for algorithm construction, and all safety states of pantographs are detected using one network.
2. Pantograph safety state detection algorithm construction
2.1 Target abstraction
Pantograph safety status detection can be divided into pantograph structure abnormality detection, pantograph fire detection, foreign object intrusion detection, etc. Among them, pantograph structure abnormality can be subdivided into carbon slide plate deformation, tilt, left and right bow angle fracture, left and right bow angle missing, etc. The standard, abnormal states are shown in Figure 1B-F.

Figure 1 Pantograph safety state and algorithm labeling standards
To use the target identification algorithm, it is first necessary to abstract the identification target to detect the safety state of the pantograph, and the abstracted identification target is shown in Figure 1. The pantographs in normal condition and abnormal state are uniformly labeled. The targets such as bow disk and bow angle in normal state and bow disk and bow angle in abnormal state and sparks and foreign objects are marked. Then the labeled data are put into a unified model for training to identify all safety states of pantographs at one time.
2.2 GAN neural network-based dataset data enhancement
After defining the detection target, we need to build our own pantograph safety state dataset to learn the necessary features from the dataset for the different states of the pantograph using deep learning methods. The data set required for algorithm construction in this paper is intercepted from several models' all-weather pantograph video surveillance. To reduce the influence of the environment on the data characteristics, the working conditions such as illumination, occlusion, cloudy days, rain and snow, entry and exit, etc., are fully considered in the process of data material preparation. The pantograph fault states in the data also set all come from the video surveillance pictures when the pantograph fault occurs in the primary running form of the motor train.
Considering that some fault types occur less frequently in actual operating conditions, which may result in inadequate data preparation. The imbalance between the category data will significantly impact the effect of target recognition, so this paper adopts a GAN neural network-based data enhancement method for different categories of data.
Generative Adversarial Network GAN contains two models, a generative model, and a discriminative model. The task of the generative model is to generate instances that look naturally realistic and similar to the original data. The task of the discriminant model is to determine whether a given example appears to be inherently real or artificially faked.
It can be seen as a zero-sum game. The generator tries to fool the discriminator, and the discriminator tries not to be fooled by the generator. The models are trained by alternate optimization, and both models can be improved. Based on these two networks, the Generator network is used to generate the image, which receives a random noise z and causes the picture by this noise, noted as G(z). The discriminator is a discriminative network that determines whether an image is "real" or not. Its input is x, x represents a picture, and the output D(x) represents the probability that x is an actual picture. If it is 1, it means a 100% accurate picture, and if the output is 0, it is impossible to be an accurate picture. Then the GAN network is schematically shown in Figure 2. x is the actual data, and the accurate data conforms to the Pdata(x) distribution. Z is the noisy data, and the noisy data conforms to the Pz(z) distribution, such as a Gaussian or a uniform distribution. Then the sampling is done from the noisy z, and the data x=G(z) is generated after passing G. Then, the actual data is fed into the classifier D, and a sigmoid function follows the generated information, and the output determines the category.

Figure 2 Schematic diagram of GAN network principle
Image-to-image transformation is a class of vision and graphics problems whose goal is to learn mappings between input and output images using a training set of aligned image pairs. Our goal is to know the G:X mapping → such that the distribution of photographs from G(X) is indistinguishable from the distribution Y using adversarial loss. Since this mapping is highly under-constrained, we couple it with an inverse mapping F: Y → and introduce a cyclic consistency loss to push F(G(X)) ≈ X (and vice versa). Qualitative results are given on several tasks where paired training data do not exist, including collection method transformation, object morphing, seasonal transformation, and photo enhancement. As much as possible, scenes are selected that are similar or similar while containing different feature images. For example, in the same scene, the camera is dirty and not dirty; the camera has pictures of rain and no rain. From the training results, we can see that if the two images selected are too different in the location, the other features included are too much will affect the training effect and the quality of image generation. And if the images generated from the selected similar scenes are of acceptable quality, the impact of data enhancement is shown in Figure 3.

Figure 3 Data set enhancement effect
In addition, this paper also adopts an oversampling method to expand the data set, combined with the YOLOV3 network, comes with data enhancement means, random packet cropping, random flipping, chroma transformation, and other operations;
The data are effectively expanded to enhance the algorithm's adaptability and provide higher robustness to detect objects in the deployment phase of practical use. However, to distinguish between the left and right bow angles, the random flip and rotation switches are turned off in the algorithm of this paper.
2.3 Optimization of recognition algorithm based on YOLOV3 network
The backbone part of YOLOV3 uses the author's Darknet53 structure, which can solve the gradient disappearance and gradient explosion problems by combining convolutional neural network (CNN) and residual structure network (ResNet), making the training of deep networks possible. In addition, the algorithm does not need to calculate the candidate boxes in advance. Still, it obtains the a priori BondingBox by clustering, selecting 9 clusters and three scales, and distributing these 9 clusters evenly on these three scales. However, due to the scale problem, the accuracy of the YOLO algorithm is not the best among the target recognition algorithms, especially in the detection of small targets. To improve the detection accuracy of the YOLOV3 algorithm while maintaining a high speed, the backbone of YOLOV3 is modified. The specific method is to add the channel attention SE module to the residual unit of darknet53. The structure of the residual network unit before and after the transformation is shown in Figure 4.

Figure 4 Residual structure of SE module before and after modification
The SE module comes from SENet, which stands for Squeeze-and-Excitation Networks, got the ImageNet 2017 classification competition championship, is recognized for its effectiveness and ease of implementation, and can easily be loaded into existing network model frameworks.SENet mainly learns the correlation between channels and filters out the attention for the channels, which slightly increases the computation, but the effect is better. The backbone part of Darknet has a total of 23 residual module units. In this paper, the original Res units are transformed into SE-Res units for some residual units. To improve the detection ability of the YOLOV3 network for small and medium targets, the residual units we changed are also located in these two branches. The overall network architecture of YOLOV3 transformed by the SE module is shown in Figure 5.

Figure 5 YOLOV3 network structure diagram
In the recognition network part, YOLOV3 is made more potent by up-sampling and cross-layer cascading to output three different scales of detection results. In the loss function design part, the target confidence, category, and position are learned at once by a cross-entropy loss function, and the loss function is shown in Equation 1.

3. Experimental results analysis
3.1 Introduction of Tienuo's intelligent analysis server
Most of the existing in-vehicle video surveillance systems only have video monitoring and storage functions but do not have the ability of intelligent online analysis. The hardware of this paper is implemented with the help of the onboard intelligent analysis server developed by Shandong Tienuo Intelligent Co., as shown in Figure 6. The host is equipped with Huawei's self-developed Da Vinci architecture AI smart chip ATLAS 3000, which can cope with innovative analysis applications in most scenarios and realize the decoding and intelligent analysis tasks of up to 16 channels of 720p video. And the test results can be transmitted to the driver's cab or the mechanic in real-time so that the test results can be manually reviewed and corresponding safety measures can be taken. This paper uses this hardware to achieve a computational speed of 60fps when running a single camera video channel. The simultaneous analysis of 4 channels of multiple videos can also ensure the calculation speed of 25fps, which can realize the demand of real-time intelligent analysis of multi-channel video.

Figure 6 Intelligent analysis server and interface diagram
3.2 Pantograph state identification results
To detect the safety state of pantographs, this paper constructs its own pantograph safety state dataset, containing 2388 pictures of various forms of pantographs, including pantographs in normal state and pantograph monitoring images in the abnormal state under different working conditions. The labeled dataset is trained using the darknet framework, and the training process is shown in Figure 7. It can be seen from the figure that the training loss remains stable after 12000 iterations, and the model may fall into a local optimum. The learning rate is adjusted once at 20000 iterations, and the loss drops to below 0.1. The improvement in computational accuracy from 20,000 iterations onward is not significant, and the corresponding mAP plot shows a slight loss in the model's generalization ability. To consider the training loss and mAP, the model with 16,000 iterations is chosen as the final model for use.

Figure 4 Pantograph safety state identification training process
To deploy the trained model to the intelligent analysis host, the trained model needs to be converted to the om format supported by the Huawei da Vinci architecture, with a slight loss of accuracy in the conversion process, but all within an acceptable range.

4. Summary and Prospect
This paper uses the YOLOV3 algorithm to detect the safety status of pantographs, including structural abnormalities, sparks, and foreign object intrusion, through real-time video monitoring, taking into account the detection speed while ensuring the accuracy of detection meets the requirements of real-time analysis. It provides new ideas for using an onboard intelligent analysis system in a pantograph safety inspection.